Вместо вводного слова, хотелось бы сразу обратить ваше внимание на используемую вами версию сборки Stable Diffusion WebUI DirectML. Если она равняется 1.8.0-RC, то добро пожаловать на страницу данного материала. В случае сборки 1.9.0 и выше, вполне возможно, что вам попросту необходимо удалить папку “venv“, после чего запустить “webui-user.bat“, чтобы перекачать в автоматическом режиме ранее удаленную папку с “правильными” файлами. Если же это не помогло, то опять таки – добро пожаловать на страницу данного материала.
Следующее, и не менее важное: ваша видеокарта AMD должна поддерживать низкоуровневый API для машинного обучения DirectML, и обладать как минимум 4 ГБ видеопамяти. Поддержкой DirectML наделены все графические адаптеры AMD основанные на архитектурах GCN 1.0, GCN 2.0 и GCN 4.0. Вот только есть нюанс в виде объема установленной VRAM. Серия Radeon HD 7000, за редкими исключениями, не выходит за рамки 3 ГБ, а этого мало для Stable Diffusion.
Если вкратце, то подойдут карты с объемом 4 ГБ+ начиная с Radeon R9 270 (проверено лично на 4-гигабайтной версии, смотрите чуть ниже)/280/285/290X/370/380/390X (6-гигабайтная HD 7970 так же подойдет, но это редкий зверек, так что…), ну и конечно же, всеми любимые RX 470/480/570/580/590/Vega 56/64. Однако следует уточнить – крайне желательно, чтобы у видеокарты было 8 ГБ VRAM и больше. Скорость генерации изображений при использовании DirectML на этом объеме ощутимо выше, и что самое важное – стабильнее.
Тем не менее, это не означает, что владельцы 4-гигабайтных карт чем-то серьезно ограничены. На подобных устройствах функционирует практически все то, что и на 8-гигабайтных графических адаптерах. Например, интеграция LoRA происходит без проблем, и генерация с ней работает более чем приемлемо.
Единственно что стоит упомянуть, так это весьма серьезные требования к объему оперативной памяти у 4-гигабайтных GPU. Тут лучше иметь более 16 ГБ ОЗУ для SD 1.5, и 32 ГБ+ для SDXL чекпоинтов/моделей, особенно если вы желаете генерировать изображения с разрешением 768×512 / 512×768 и выше.
Дисклеймер: Все нижеописанные действия и настройки помогли именно в моем случае (операционная система – Windows 11, железо – R9 270X 4 GB, RX 470 4 GB и RX 470 8 GB). Существует неиллюзорная вероятность, что мой опыт вам не поможет.
Системные требования, и необходимое ПО
Для начала, давайте убедимся что вы выполнили все соответствующие требования для дальнейшего успешно запуска Stable Diffusion WebUI, с бекендом DirectML.
Минимальные системные требования:
- Операционная система: Windows 10/11;
- Объем оперативной памяти: 16 ГБ и больше;
- Процессор: 4-ядерный чип Intel Core i5-2400, или AMD FX-4300 или лучше;
- Видеокарта: Radeon R9 270 4 ГБ, Radeon RX 470 4 ГБ или лучше;
- Накопитель (желательно SSD, но скоростной HDD тоже подойдет): около 10 ГБ свободного места для установки, и до умопомрачительных объемов в 100 и 300 ГБ. Все зависит от того, насколько много чекпоинтов/моделей вы собираетесь использовать.
Необходимое программное обеспечение:
Актуальная сборка stable-diffusion-webui-directml из официального источника:
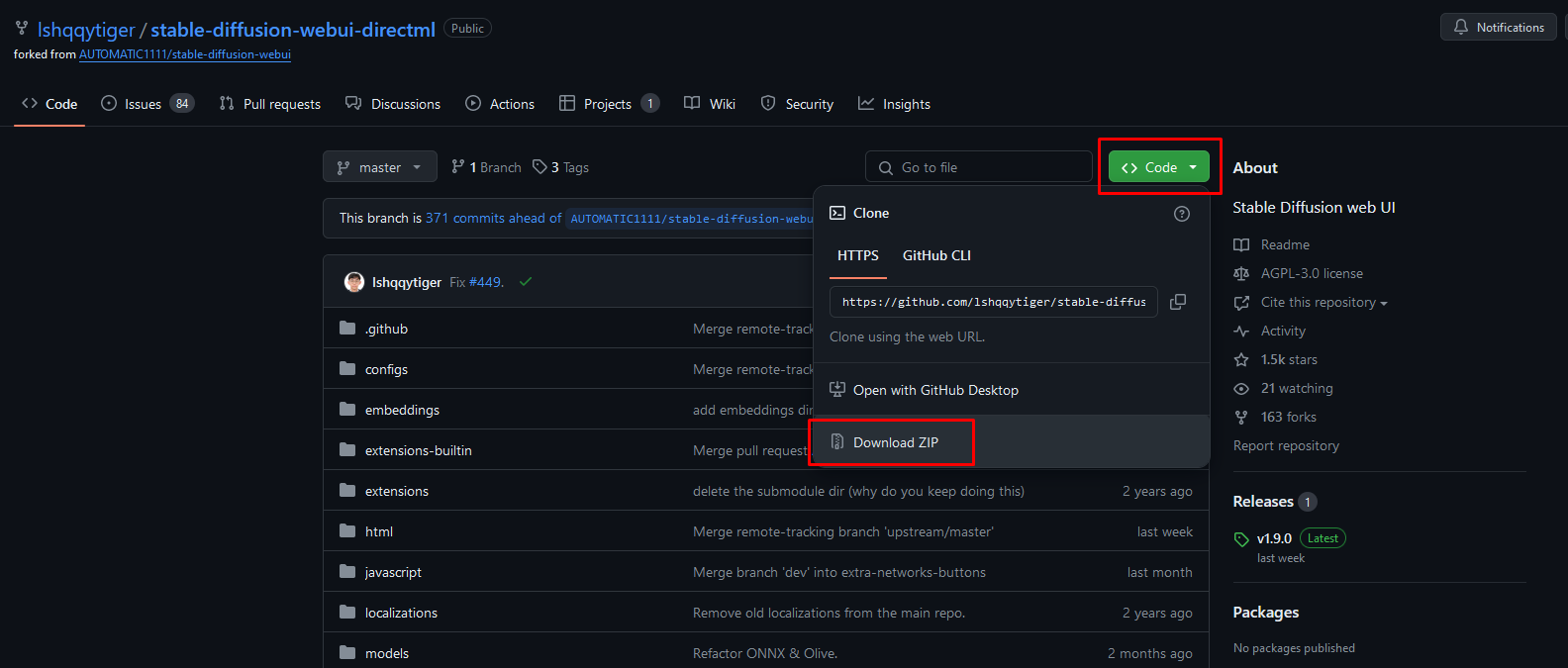
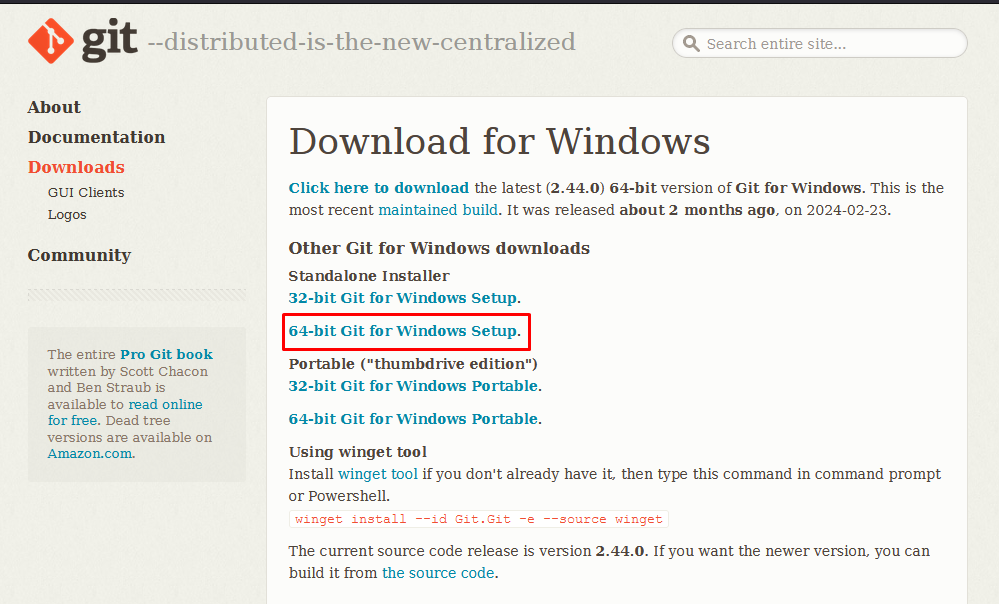
64-bit версия Git for Windows:
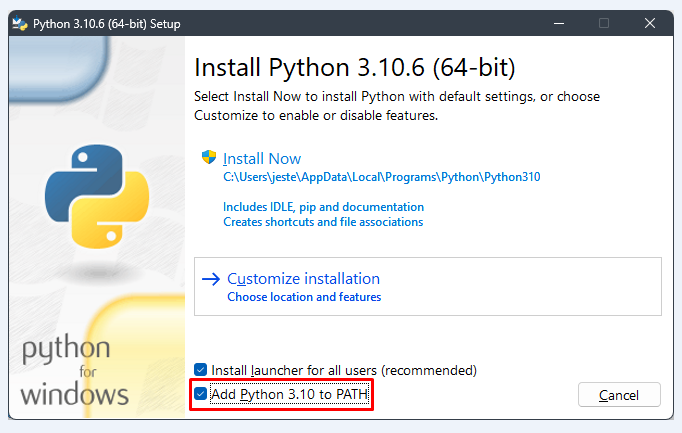
64-bit версия Python 3.10.6 (при установке ОБЯЗАТЕЛЬНО поставьте галочку на пункте Add Python 3.10 to PATH).
Установка и запуск Stable Diffusion WebUI
Все пункты успешно выполнены? Тогда распаковываем архив со Stable Diffusion WebUI в корень любого диска. В зависимости от потребностей, вы можете переименовать архив и/или папку, это ни на что не повлияет, главное, чтобы в названии папки не было пробелов. Я так и поступил, так как у меня несколько тестовых экземпляров.

Заходим в распакованную папку, и нажимаем правым кликом на файл “webui-user.bat“, далее щелкаем по пункту “изменить/открыть с помощью Code” (для редактирования можно использовать как стандартный блокнот, так и Microsoft VS Code):

Здесь вам нужно прописать аргументы для запуска нейросети.
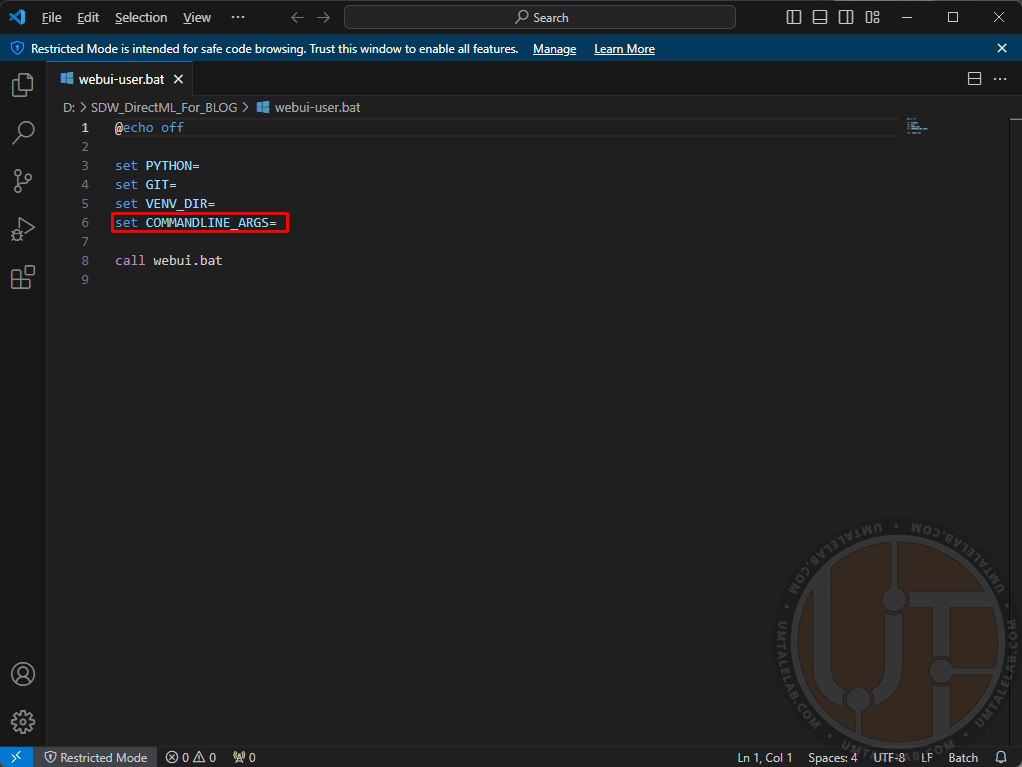
Для первого успешного старта Stable Diffusion WebUI DirectML лучше не использовать лишних параметров, и остановиться на следующих:
Для видеокарт с 4 ГБ видеопамяти:
set COMMANDLINE_ARGS= --use-directml --lowvramДля видеокарт с 8 ГБ видеопамяти:
set COMMANDLINE_ARGS= --use-directml --medvramДля видеокарт с 16 ГБ видеопамяти и больше:
set COMMANDLINE_ARGS= --use-directml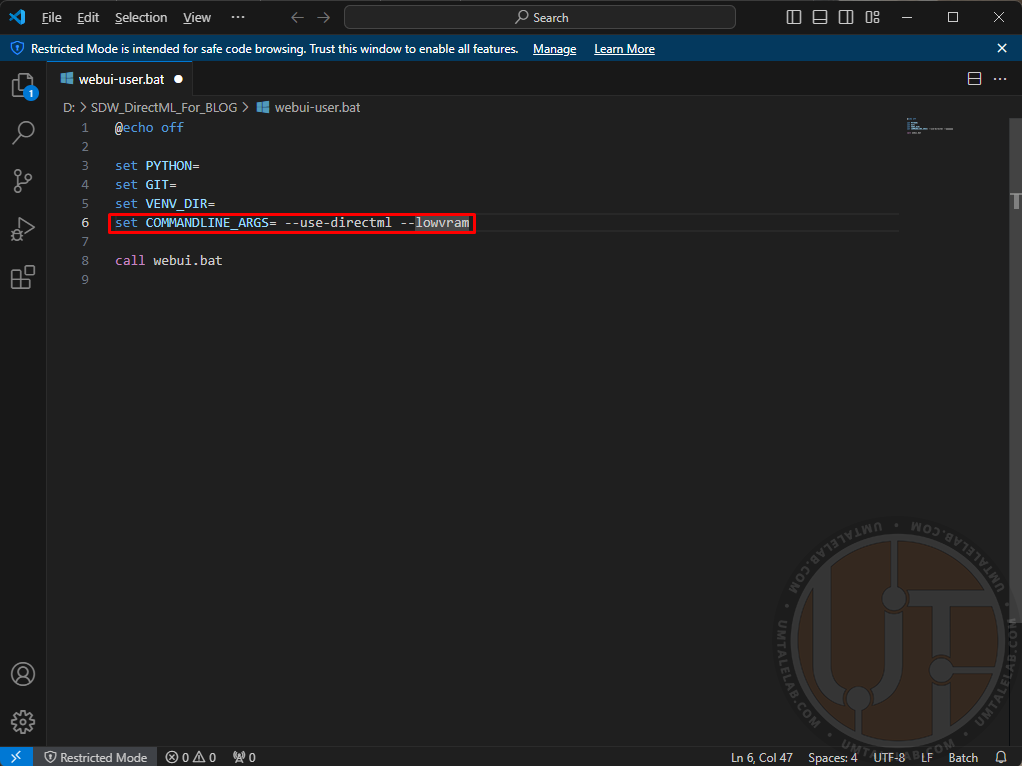
Аргумент --use-directml указывает сборке принудительно переключиться на соответствующий бекенд, и загрузить на ваш ПК совместимые библиотеки. --lowvram призван снизить потребление видеопамяти, в ущерб скорости генерации (в том числе за счет ОЗУ). --medvram так же немного снижает скорость генерации, но уже не так существенно как --lowvram.
Сохраняем файл (файл>сохранить, либо сочетанием клавиш CTRL + S) и запускаем измененный батник. Откроется окно командной строки. Далее вас ждет весьма продолжительная установка всех необходимых ассетов и библиотек (в зависимости от мощности вашего ПК и скорости интернета – от 10 минут до 1 часа). В какой-то момент может показаться что установка зависла, но вероятнее всего это не так. Просто подождите еще немного.

После завершения установки консоль автоматически запустит браузер, в котором откроется вкладка с адресом http://127.0.0.1:7860/. Если этого не произошло, то просто скопируйте ранее упомянутую ссылку и вставьте в адресную строку браузера.

Крайне важно: ни в коем случае не закрывайте консоль! Это и есть ваш личный сервер с нейросетью, а вкладка в браузере – просто графический интерфейс взаимодействия с ним.
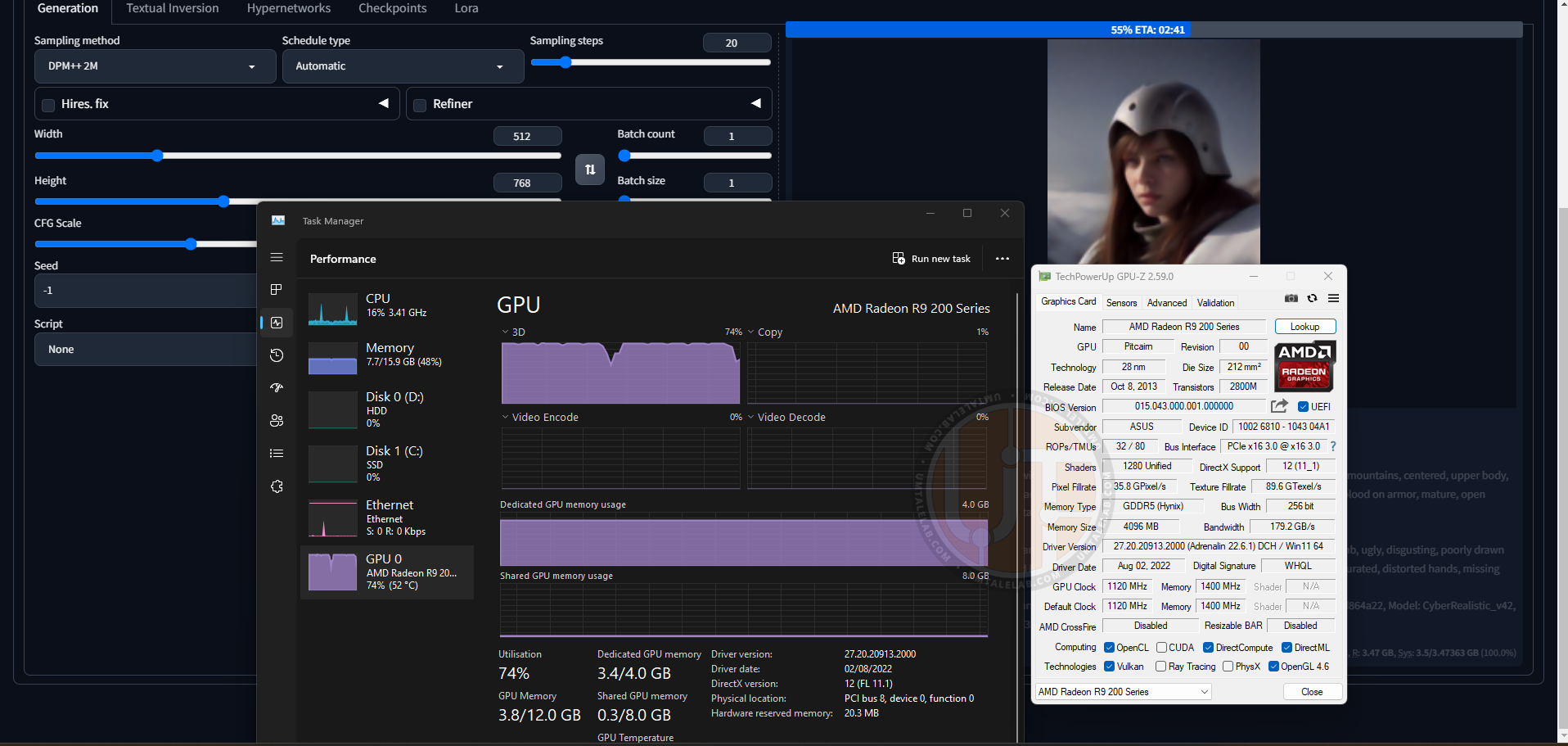
Теперь давайте проверим, работает ли наша нейросеть. На данном этапе я не загружал никаких дополнительных моделей, поэтому буду использовать базовую SD 1.5. Впишем простенький prompt “knight” и вуаля, генерируя наше изображение, графический процессор 4-гигабайтной видеокарты RX 470 загружен практически под завязку:
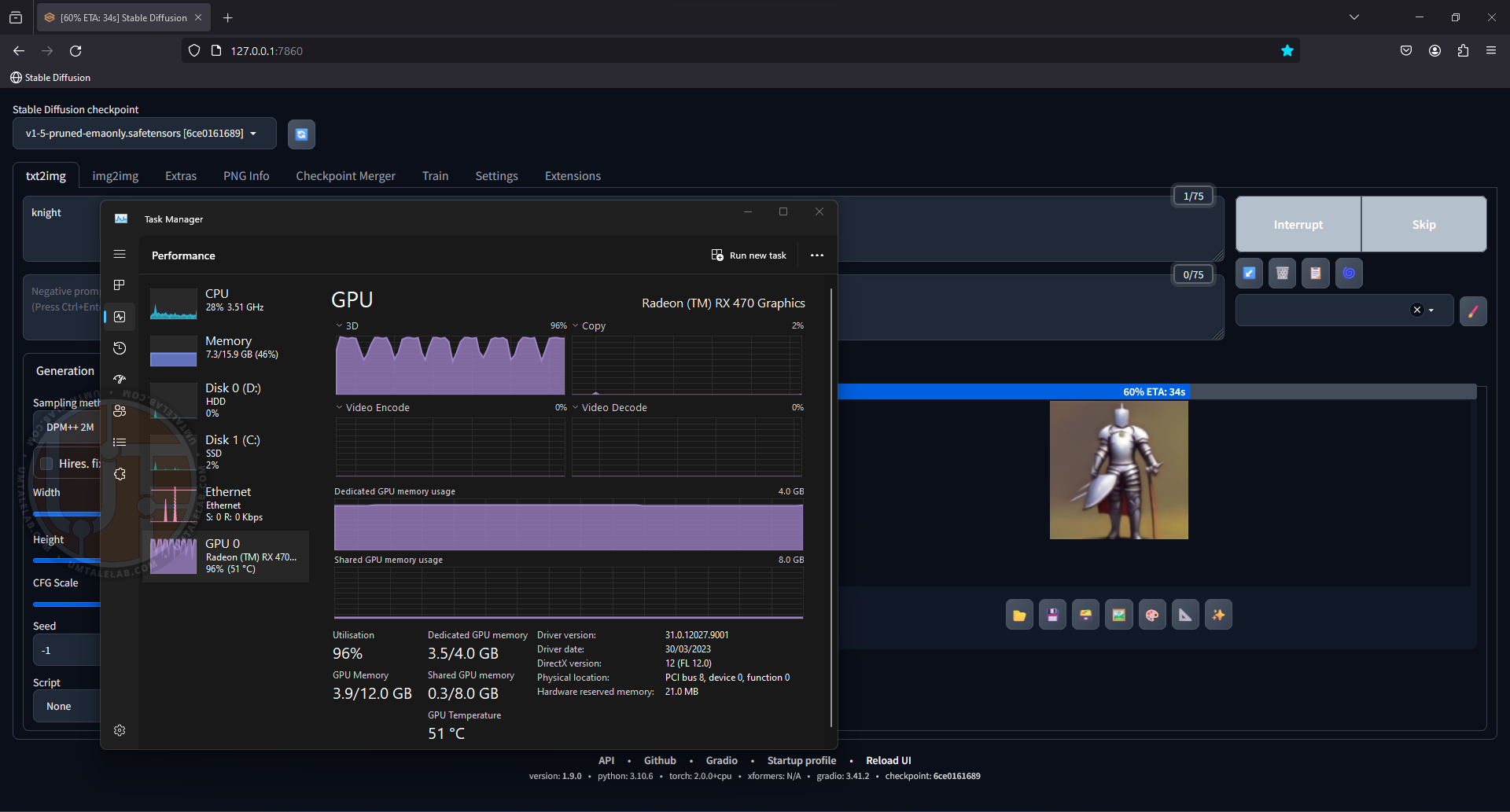

Даже на видеокарте со скромным объемом VRAM, скорость генерации существенно выше, чем на классическом центральном процессоре.
К слову, а вот и генерация заглавного изображения для данного материала силами 4-гигабайтной RX 470. Здесь я уже использую сторонний чекпоинт CyberRealistic v4.2, вдобавок с двумя LoRA:
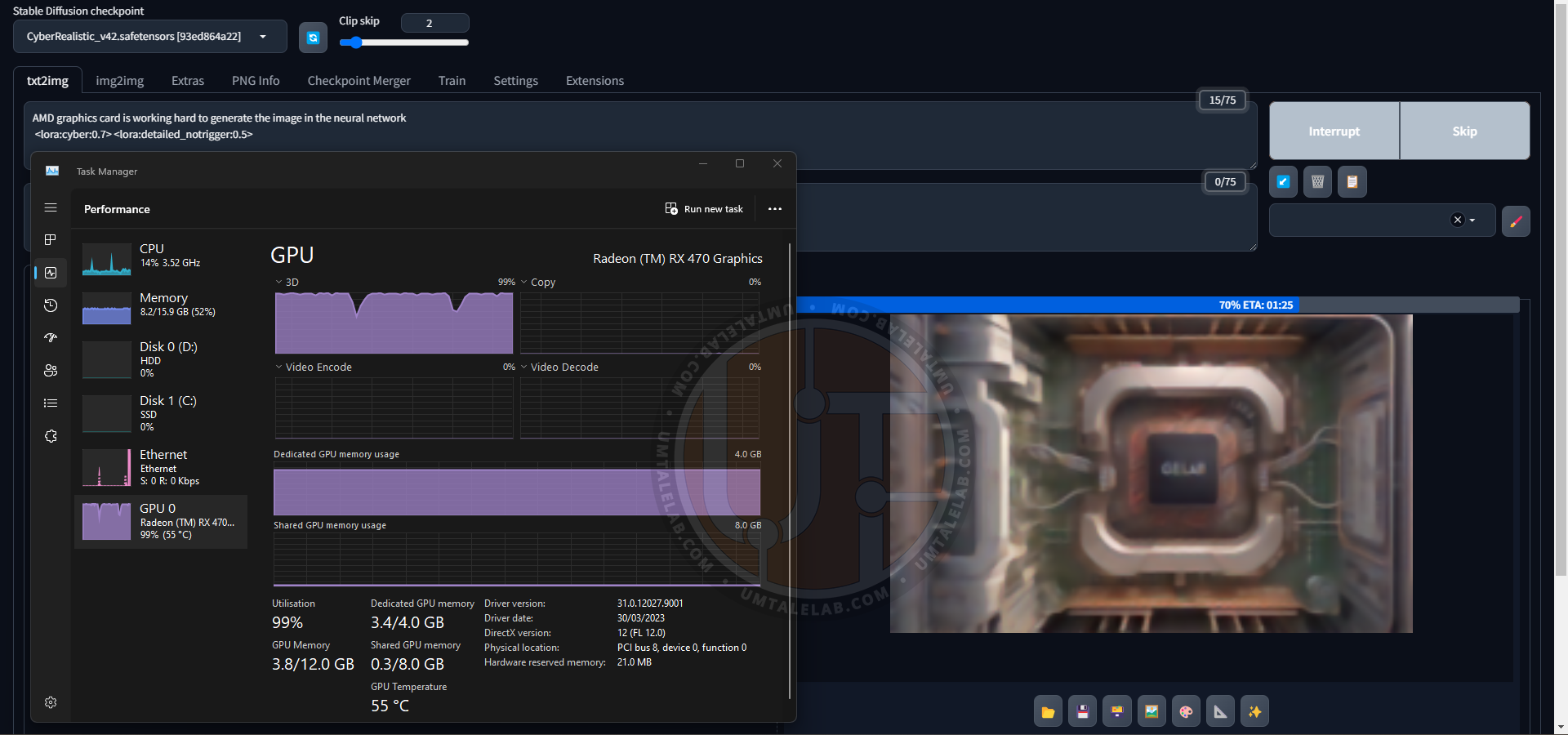
По итогу я лишь немного подкорректировал контрастность, и заменил логотип на AMD в растровом редакторе изображений.
В целом, это все. Сервер работает, интерфейс доступен, можете смело приступать к генерации потенциальных шедевров! А вот если у вас возникли проблемы с запуском, или генерация стопориться из-за ошибок – то добро пожаловать в следующий раздел данного материала.
Решение потенциальных проблем после установки Stable Diffusion WebUI
В случае возникновения разнообразных ошибок при запуске (вроде злосчастной “Torch is not able to use GPU”), или попытке генерации изображений в Stable Diffusion WebUI DirectML, вам стоит попробовать проделать следующие действия:
Зайдите в директорию с нейросетью, и удалите папку venv:

Далее, в директории с нейросетью найдите файл requirements_versions.txt и нажмите на него правой кнопкой мыши, после чего щелкните по пункту “изменить/открыть с помощью Code”.
В этом файле вам нужно найти запись о необходимой библиотеке torch, она расположена примерно на 29-33 строке, в зависимости от сборки WebUI:
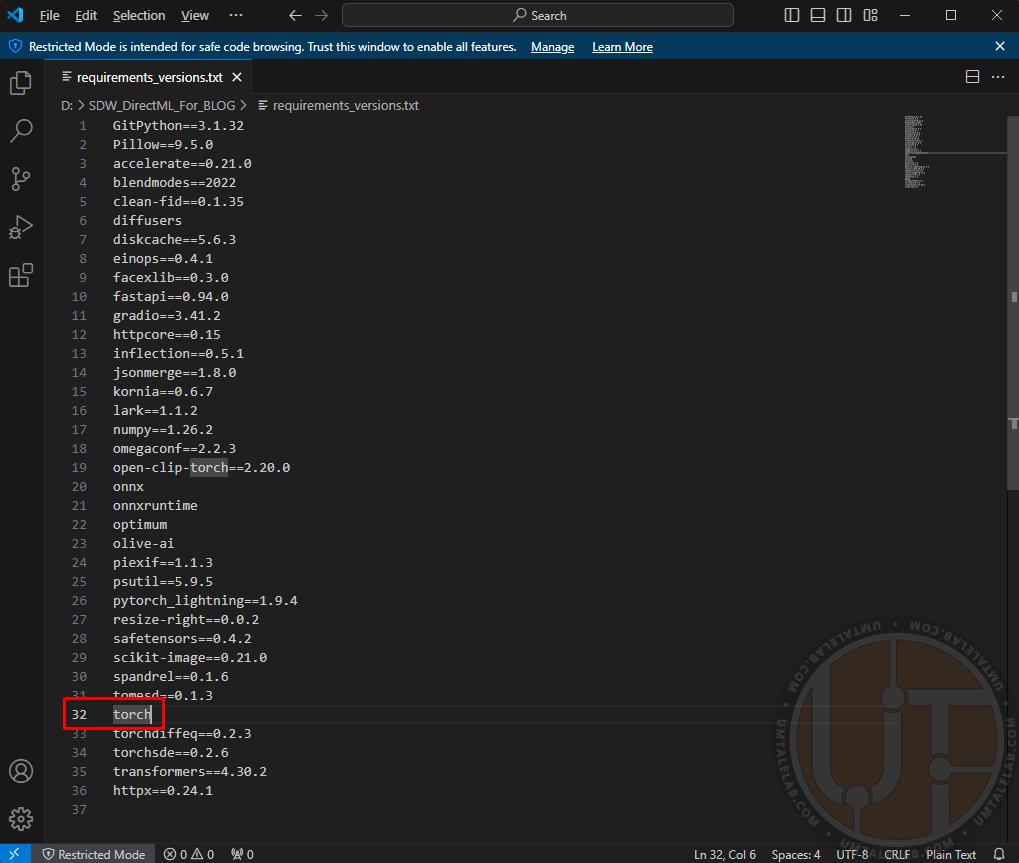
Эту запись вам нужно изменить на torch-directml:

Сохраняемся и закрываем данный файл. Следом за этим, нажимаем правой кнопкой мыши на файл “webui-user.bat“, далее щелкаем по пункту “изменить/открыть с помощью Code”. Здесь вам нужно к уже прописанным ранее параметрам добавить следующий аргумент --reinstall-torch:
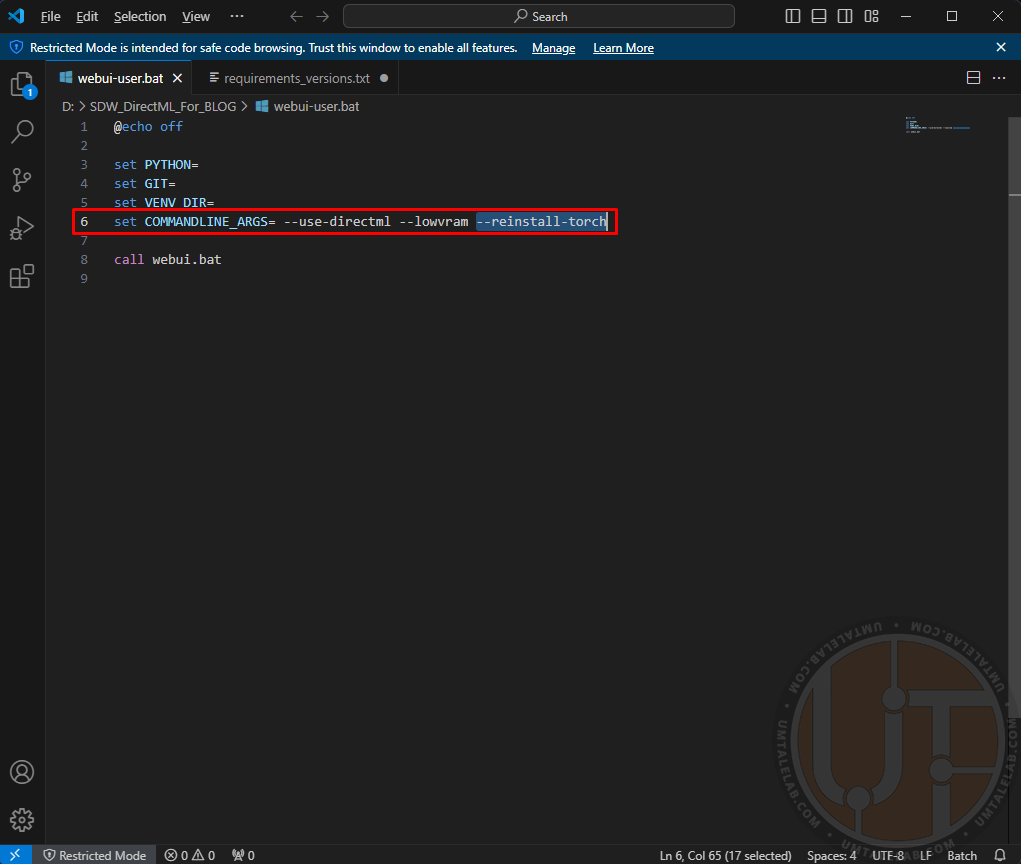
Сохраняемся и запускаем этот же файл. Таким образом мы переустанавливаем библиотеки torch исключительно под DirectML (и CPU, но нам это не интересно).
После того, как консоль вновь загрузит необходимые файлы и откроется веб-интерфейс Stable Diffusion, аргумент --reinstall-torch из батника webui-user.bat можно удалять.
В моем случае это помогло с решением ошибки “Torch is not able to use GPU” на одной из сборок Stable Diffusion WebUI DirectML. На другой сборке избавило от проблемы использования процессора вместо видеокарты AMD.
Дополнительные настройки и примеры работы Stable Diffusion WebUI на 4 и 8 ГБ видеокартах AMD
В данном разделе я опишу свой опыт работы с нейросетью на слабых видеокартах AMD, а так же приведу несколько примеров генерации изображений на графических адаптерах R9 270X и RX 470.
Согласно моим исследованиям, лишь два аргумента позволяют получить существенный прирост производительности на видеокартах AMD. Первый это --opt-sdp-attention, который, если не вдаваться в подробности, является аналогом xFormers для карт NVIDIA, но в отличии от последнего, работает и на красных графических адаптерах. --opt-sdp-attention действительно ускоряет генерацию изображений, однако это далеко не бесплатно. Ценой за повышенную скорость становится видеопамять, которой, с бекендом DirectML и так постоянно не хватает.
Второй аргумент – это --upcast-sampling. Генерацию он ускоряет он незначительно, но при этом слегка уменьшает потребление видеопамяти, что весьма уместно.
Параметры запуска Stable Diffusion WebUI для 4-гигабайтных карт R9 270X и RX 470:
set COMMANDLINE_ARGS= --use-directml --lowvramПо какой-то причине, параметр --upcast-sampling лишь вредит картам с малым объемом видеопамяти. При использовании этого аргумента, скорость генерации падает в два-три раза. Хотя, судя по описанию в документации, он вроде как призван слегка оптимизировать потребление той самой видеопамяти, и немного ускорить генерацию.
Использовать --opt-sdp-attention на 4 ГБ видеокартах вообще невозможно. Генерация даже не запускается, вываливаясь с ошибкой о критической нехватке памяти практически при любом разрешении.
Увы, но в моем случае эти параметры не помогли 4-гигабайтным картам. Тем не менее, вы вполне можете провести соответствующие эксперименты на своем ПО и оборудовании. Возможно в вашем случае вышеупомянутые параметры адекватно заработают на картах со скромным объемом VRAM.
Процесс генерации одного из изображений на Radeon R9 270X в разрешении 512 на 768 пикселей:
Финальный результат:

Время генерации – чуть больше 5 минут, при 20 sampling steps, а так же одной подключенной LoRA. Для столь старой видеокарты – достойнейший результат.
Еще один финальный результат:

А теперь давайте посмотрим, за сколько справится RX 470 4GB с аналогичными настройками и разрешением:

Уже лучше – 3 минуты 23 секунды.
Ну и самое интересное я оставил под конец. В тестовом стенде RX 470 на 8 ГБ.
Параметры запуска Stable Diffusion WebUI для 8-гигабайтных карт:
set COMMANDLINE_ARGS= --use-directml --medvram --opt-sdp-attention --upcast-samplingВ случае относительно достаточного объема видеопамяти, параметры --opt-sdp-attention и --upcast-sampling работают как прописано в документации, и действительно существенно ускоряют генерацию изображений, а так же немного снижают потребление VRAM.
Без --opt-sdp-attention и --upcast-sampling:

Генерация продлилась 2 минуты 53 секунды. Прирост относительно 4-гигабайтной версии совсем несущественный.
С --opt-sdp-attention и --upcast-sampling:
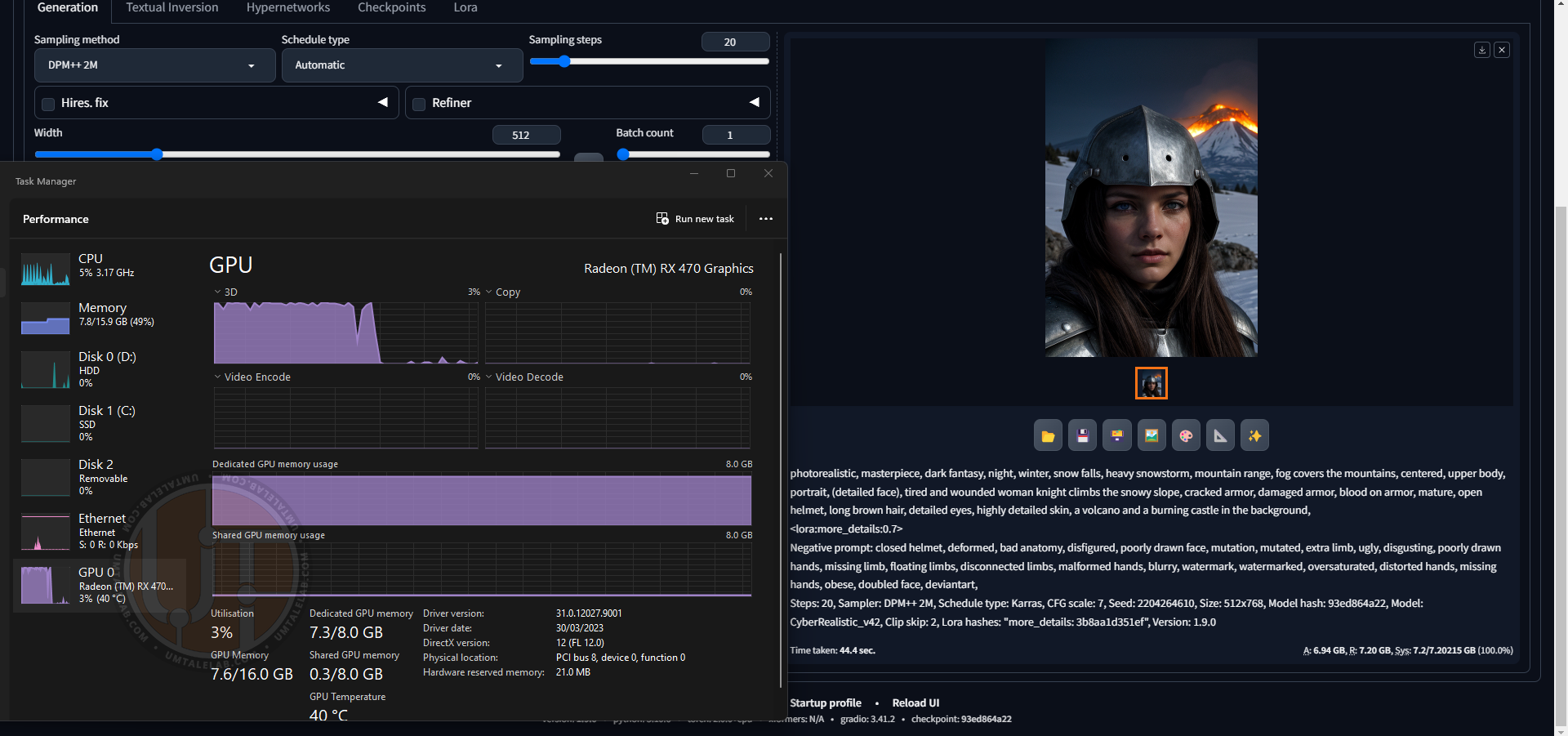
А вот это уже другое дело – всего 44 секунды! Ровно как я и писал в начале материала, 8-гигабайтные версии RX 470/480/570/580/590 будут генерировать изображения гораздо быстрее своих 4-гигабайтных сородичей.
Давайте попробуем немного увеличить разрешение до 512 на 900:

53 секунды – отменный результат! Но тут мы достигли предела 8-гигабайтных видеокарт. Если вы желаете генерировать изображения в более высоком разрешении, вам необходимо использовать аргумент --lowvram и для подобного объема VRAM.
Теперь немного про несущественные ошибки, которые в целом не мешают работе Stable Diffusion.
Периодически, при генерации изображений в разрешении 512×768 / 768×512 (высоком для карт AMD), может выскакивать ошибка “RuntimeError: Could not allocate tensor with 1207959552 bytes (или любое другое количество байт). There is not enough GPU video memory available!”. Вероятно, это нормально для ветки Stable Diffusion WebUI с бекендом DirectML, настройки и/или разрешение менять не имеет особого смысла, так как после повторного запуска генерация может начаться как ни в чем не бывало, и сделать хоть 50 изображений подряд (в батче или без него, значения не имеет), а потом снова на первом вывалиться в “RuntimeError”.
Похоже на проблемы с “утечкой видеопамяти”, но ручаться за это я не могу, так как выяснить причину подобного поведения WebUI DirectML мне не удалось.
Итог
Безусловно, скорость генерации на видеокартах AMD, по сравнению с графическим адаптерами NVIDIA оставляет желать лучшего. Тем не менее, если в вашем системном блоке установлена карта от красного гиганта – это далеко не приговор. Согласно моим исследованиям, GPU от AMD (особенно с относительно большим объемом видеопамяти), способны достаточно быстро генерировать изображения даже с использованием нескольких LoRA. А если вы счастливый обладатель карты с 16, или 24 гигабайтами VRAM, то вам открывается доступ к созданию изображений с более высоким разрешением, вплоть до FullHD. Возможно даже выше. Видеокарт AMD с подобным объем видеопамяти в наличии у меня сейчас нет.
Было бы приятно оценить ваши результаты генерации изображения на видеокартах AMD. Кроме этого, если у вас есть информация о дополнительных настройках, или библиотеках, которые могут ускорить работу Stable Diffusion на красных графических адаптерах – не стесняйтесь делиться своим опытом в комментариях к этому материалу!






