Rather than an introduction, I would like to direct your attention to the Stable Diffusion WebUI DirectML build you are using. If it is 1.8.0-RC, then welcome to this article. If it is 1.9.0 or higher, it is possible that you simply need to delete the “venv” folder and then run “webui-user.bat” to automatically download the previously deleted folder with the “correct” files. If that doesn’t work, then again – welcome to this material page.
Next, and no less important: your AMD graphics card must support the low-level machine learning API DirectML, and have at least 4 GB of video memory. DirectML support is available for all AMD graphics adapters based on GCN 1.0, GCN 2.0 and GCN 4.0 architectures. Only there is a nuance in the form of the amount of installed VRAM. Radeon HD 7000 series, with rare exceptions, does not go beyond 3 GB, and this is not enough for Stable Diffusion.
In a nutshell, you can use 4 GB+ graphics cards starting with Radeon R9 270 (tested personally on the 4GB version, see below)/280/285/290X/370/380/390X (6GB HD 7970 will also work, but it’s a rare beast, so…), and of course, the beloved RX 470/480/570/580/590/Vega 56/64. However, it should be clarified – it is highly desirable that the graphics card has 8GB of VRAM or more. Image generation speed when using DirectML on this memory size is noticeably higher, and what is most important – more stable.
Nevertheless, this does not mean that owners of 4GB cards are seriously limited in any way. On such devices almost everything that can be performed on 8GB graphics adapters functions. For example, LoRA integration happens without any problems, and generation with it works more than acceptably.
The only thing worth mentioning is the very serious RAM requirements of 4GB GPUs. It’s better to have more than 16GB RAM for SD 1.5, and 32GB+ for SDXL checkpoints/models, especially if you want to generate images with resolutions of 768×512 / 512×768 and higher.
Disclaimer: All of the following actions and settings helped in my case (operating system – Windows 11, hardware – R9 270X 4 GB, RX 470 4 GB and RX 470 8 GB). There is a certain probability that my experience will not help you.
System requirements and necessary software
First, let’s make sure that you have met all the relevant requirements to continue successfully running the Stable Diffusion WebUI, with the DirectML backend.
Minimum System Requirements:
- OS: Windows 10/11;
- Amount of RAM: 16GB or more;
- CPU: 4-core Intel Core i5-2400, or AMD FX-4300 or better;
- Graphics card: Radeon R9 270 4GB, Radeon RX 470 4GB or better;
- Storage (preferably SSD, but a high-speed HDD will work too): about 10 GB of free space for installation, and up to mind-boggling amounts of 100 and 300 GB. It all depends on how many checkpoints/models you are going to use.
Required software:
Actual build of stable-diffusion-webui-directml from the official source:
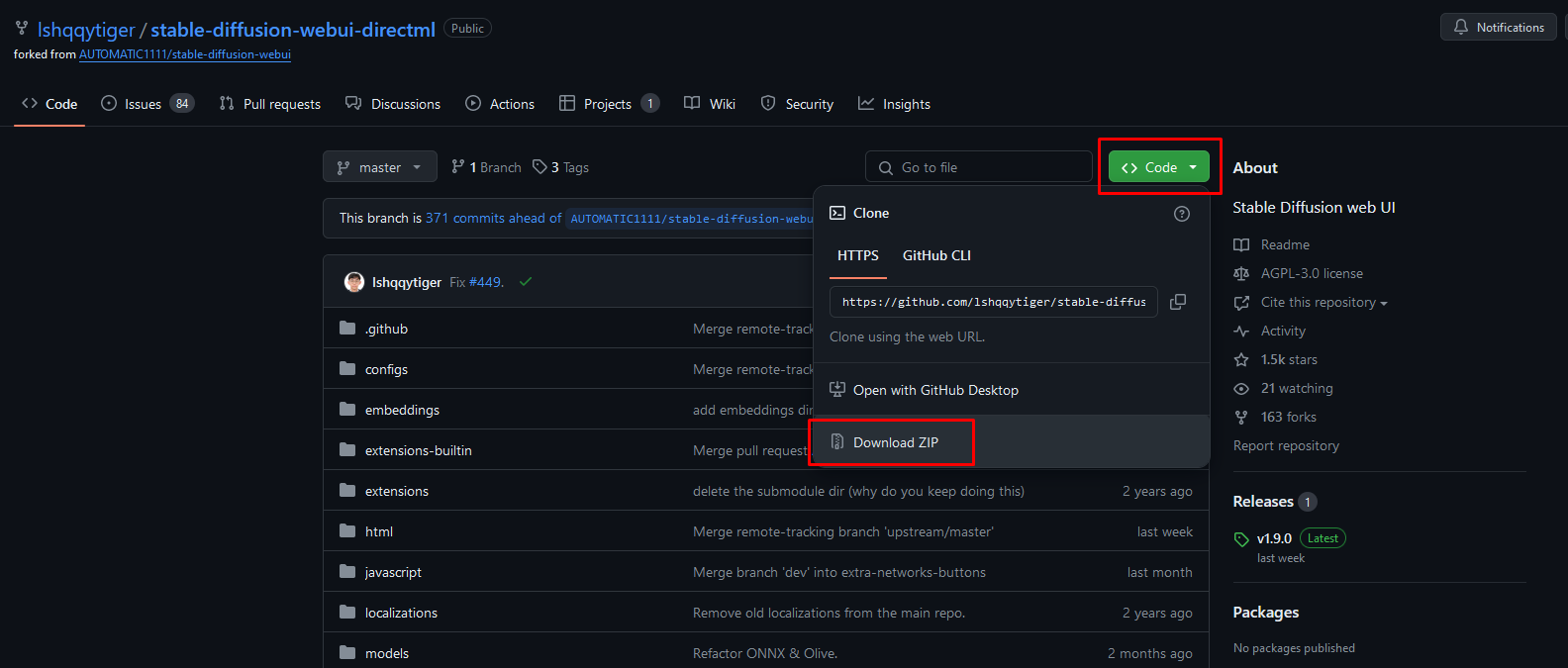
64-bit version of Git for Windows:
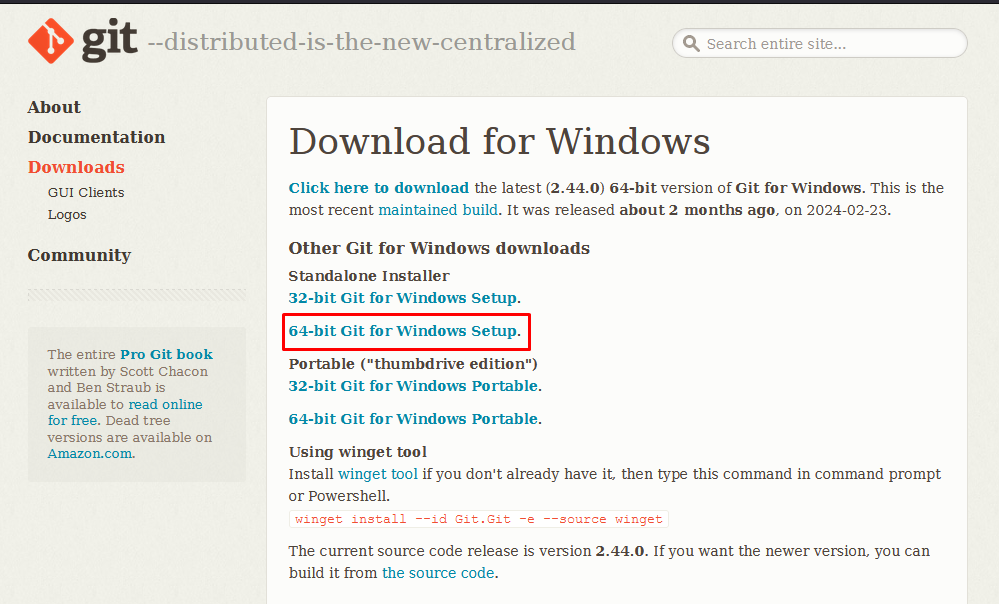
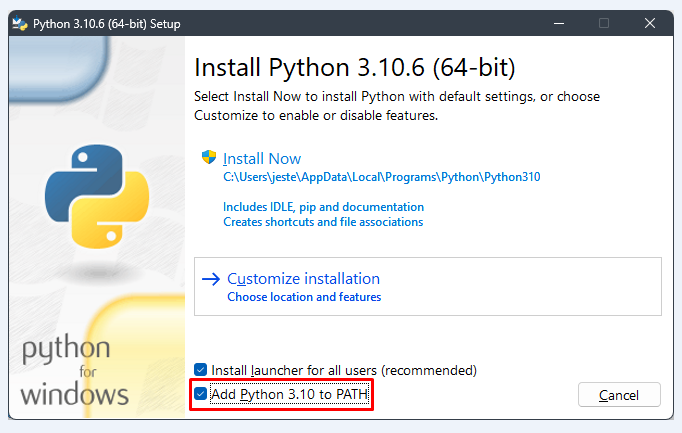
64-bit version of Python 3.10.6 (you MUST check Add Python 3.10 to PATH when installing).
Installing and running Stable Diffusion WebUI
Have you successfully completed all the steps? Then extract the archive with Stable Diffusion WebUI to the root of any disk. Depending on your needs, you can rename the archive and/or folder, it won’t affect anything, as long as there are no spaces in the folder name. That’s what I did, as I have several test instances.

Go to the extracted folder, and right-click on the file “webui-user.bat“, then click on the item “edit/open with Code” (you can use standard Notepad or Microsoft VS Code for editing):

Here you need to specify the arguments to run the neural network.
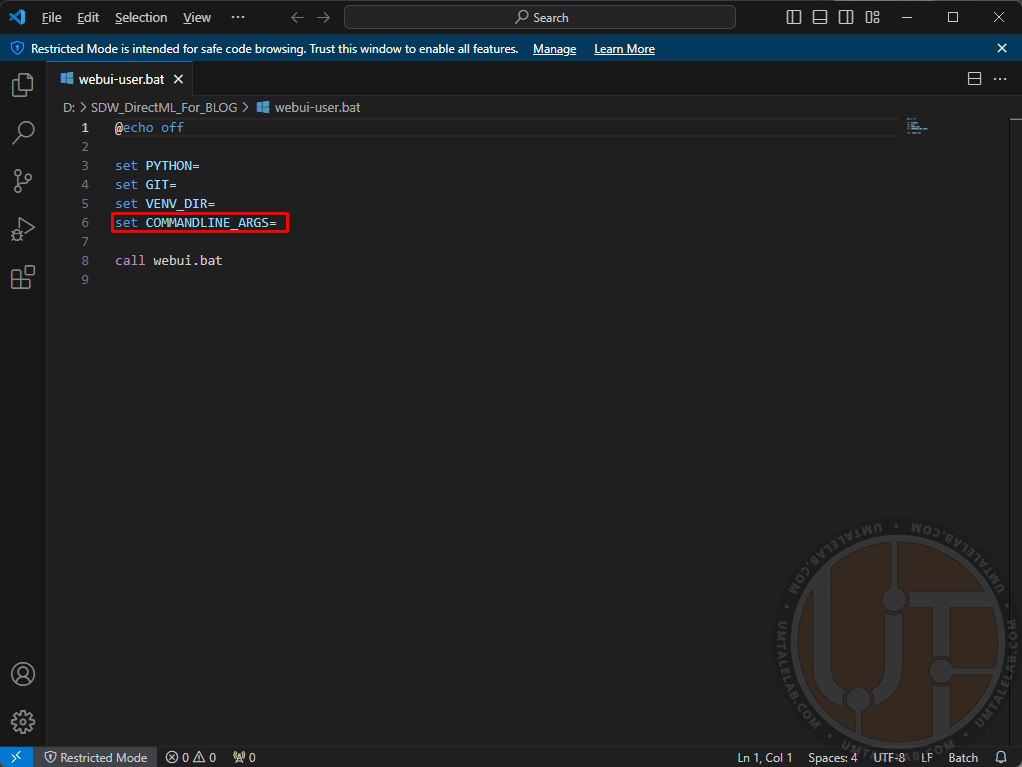
For the first successful start of Stable Diffusion WebUI DirectML it is better not to use unnecessary parameters, and to stop on the following:
For graphics cards with 4GB of video memory:
set COMMANDLINE_ARGS= --use-directml --lowvramFor graphics cards with 8GB of video memory:
set COMMANDLINE_ARGS= --use-directml --medvramFor graphics cards with 16GB of video memory or more:
set COMMANDLINE_ARGS= --use-directml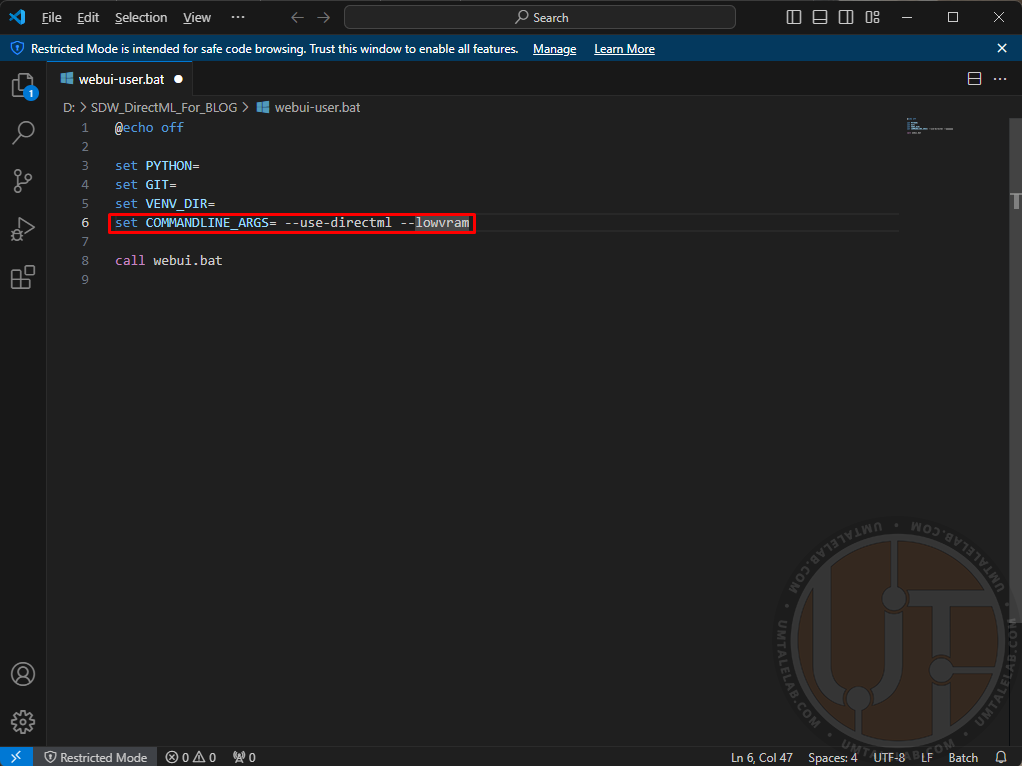
The --use-directml argument tells the build to force a switch to the appropriate backend and load compatible libraries on your PC. --lowvram is intended to reduce video memory consumption, to the detriment of generation speed (including at the expense of RAM). --medvram also slightly reduces generation speed, but not as much as --lowvram.
Save the file (file>save or CTRL + S) and run the modified batch file. A command line window will open. Then you will be waiting for a very long installation of all the necessary assets and libraries (depending on the power of your PC and internet speed – from 10 minutes to 1 hour). At some point it may seem that the installation hangs, but most likely it is not. Just wait a little longer.

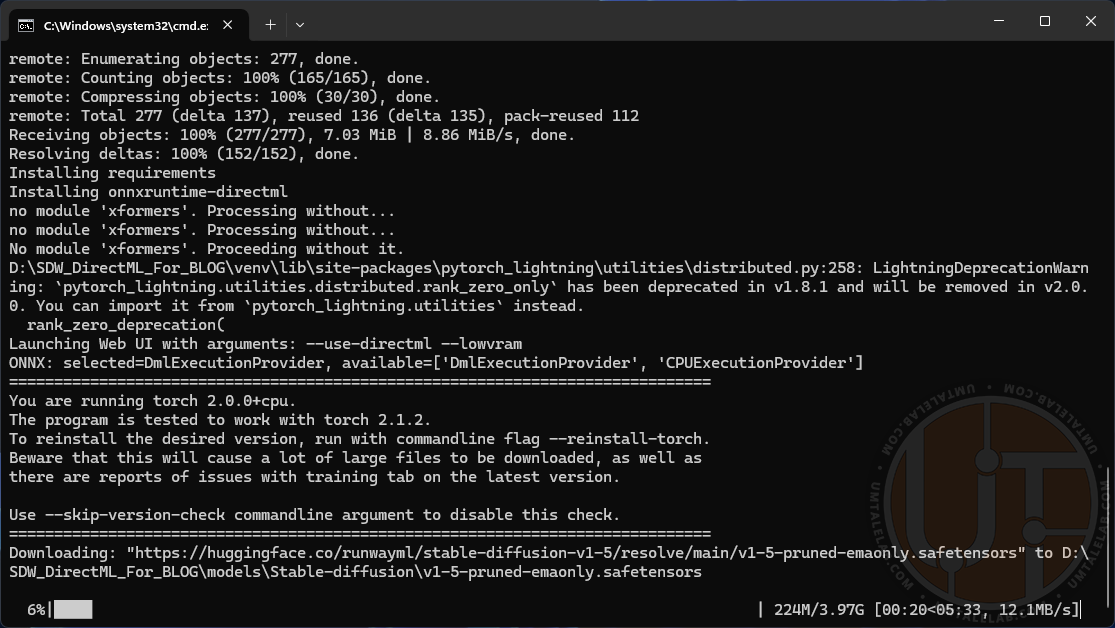
After the installation is complete, the console will automatically launch the browser, which will open a tab with the address http://127.0.0.1:7860/. If this does not happen, simply copy the previously mentioned link and paste it into the browser address bar.

It is extremely important: never close the console! This is your personal server with the neural network, and the tab in the browser is just a graphical interface for interacting with it.
Now let’s check if our neural network works. At this stage I have not loaded any additional models, so I will use the basic SD 1.5. Let’s type in a simple prompt “knight” and voila, generating our image, the graphics processor of the 4GB RX 470 graphics card is loaded almost to the brim:
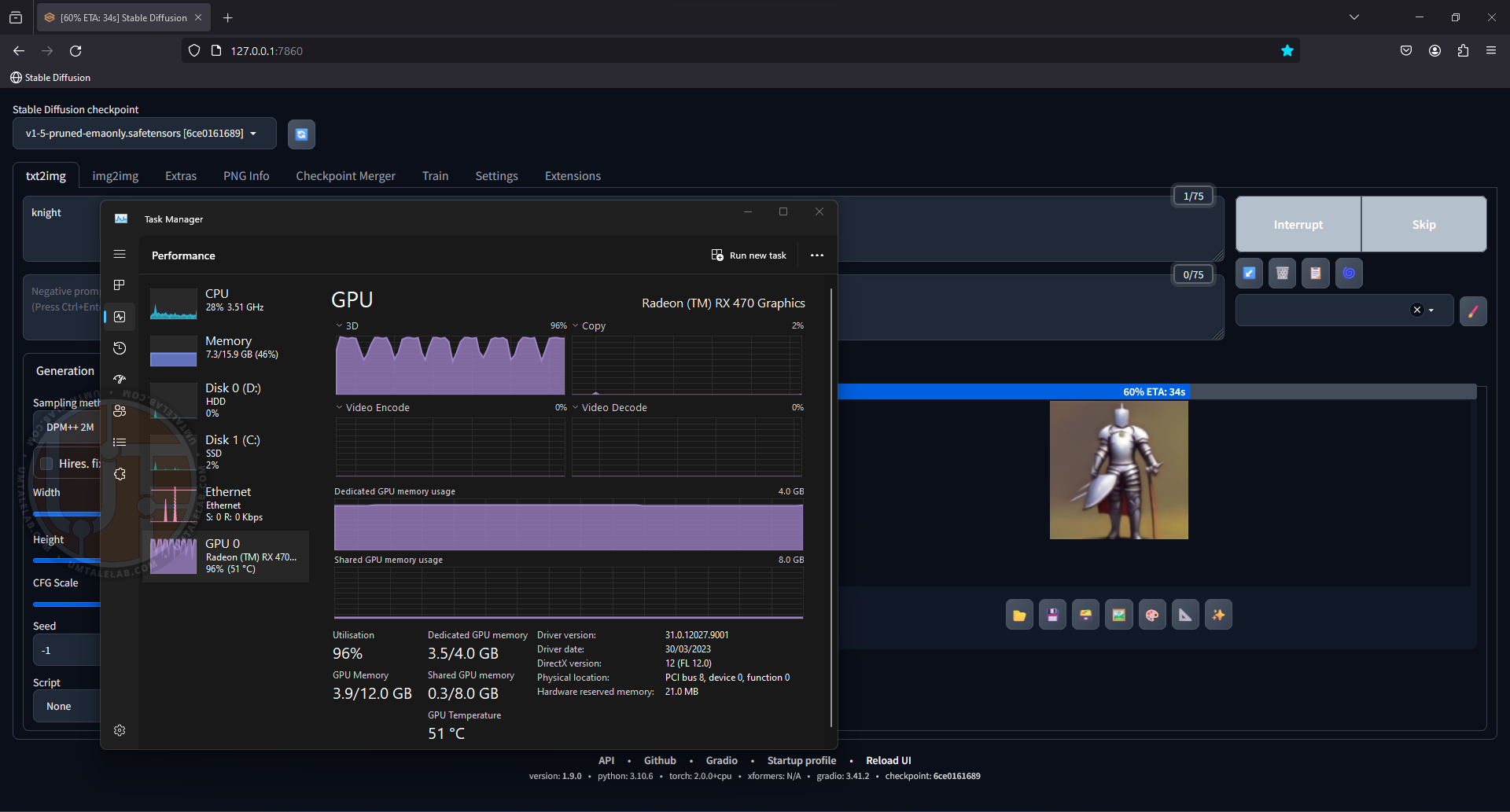

Even on a graphics card with a modest amount of VRAM, the generation speed is significantly faster than on a classic CPU.
By the way, here is the generation of the title image for this article by the 4GB RX 470. Here I am already using a third-party checkpoint CyberRealistic v4.2, in addition with two LoRA:
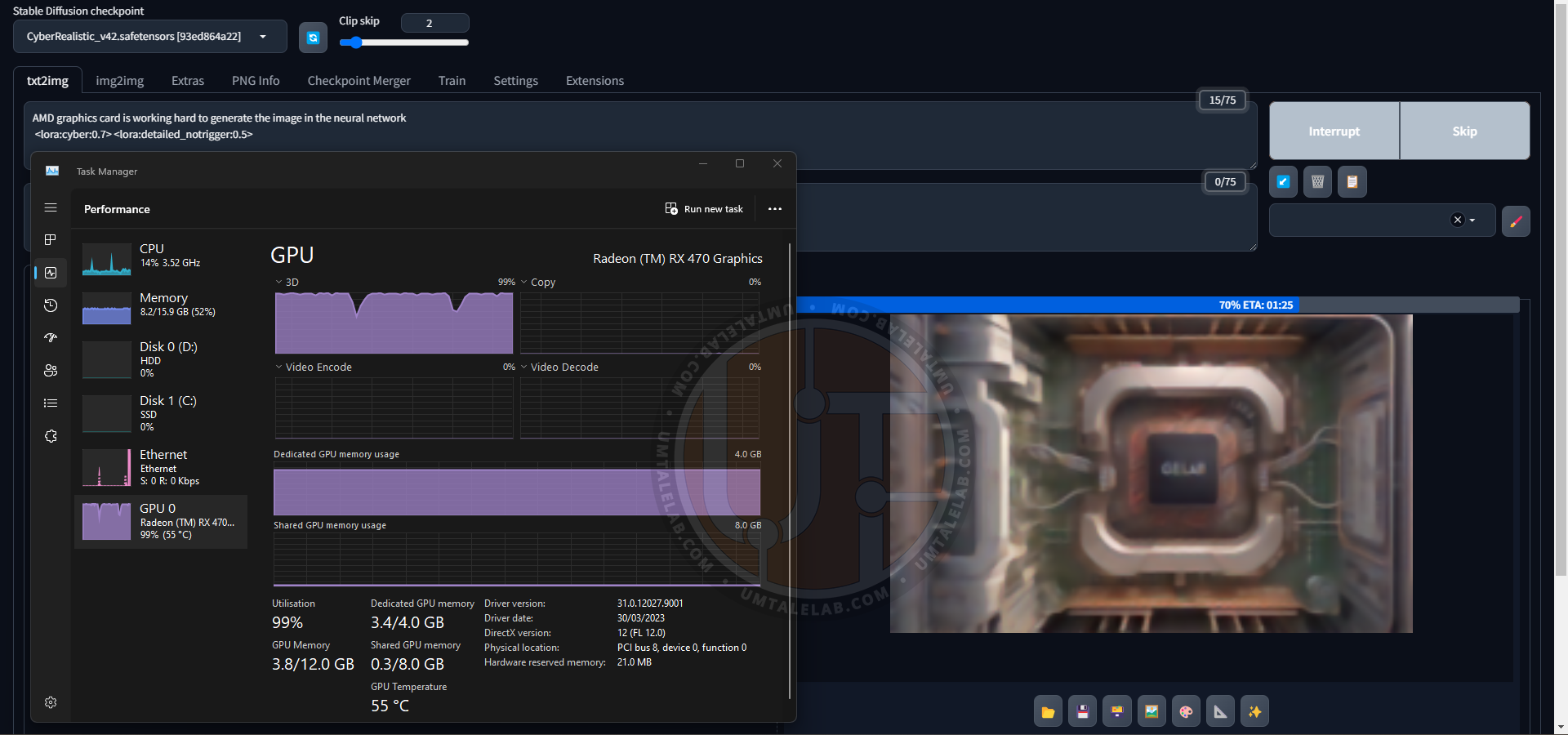
In summary, I only tweaked the contrast a bit, and placed the AMD logo in a raster image editor.
All in all, that’s it. The server works, the interface is available, you can start generating potential masterpieces! But if you have problems with startup, or generation is stalled due to errors – then welcome to the next section of this material.
Solving potential problems after installing Stable Diffusion WebUI
In case of various startup errors (like the unfortunate “Torch is not able to use GPU”), or trying to generate images in Stable Diffusion WebUI DirectML, you should try the following steps:
Go to the directory with the neural network, and delete the venv folder:

Next, in the neural network directory, find the requirements_versions.txt file and right click on it, then click on “modify/open with Code”.
In this file you need to find an entry for the required torch library, it is located on about line 29-33, depending on the WebUI build:
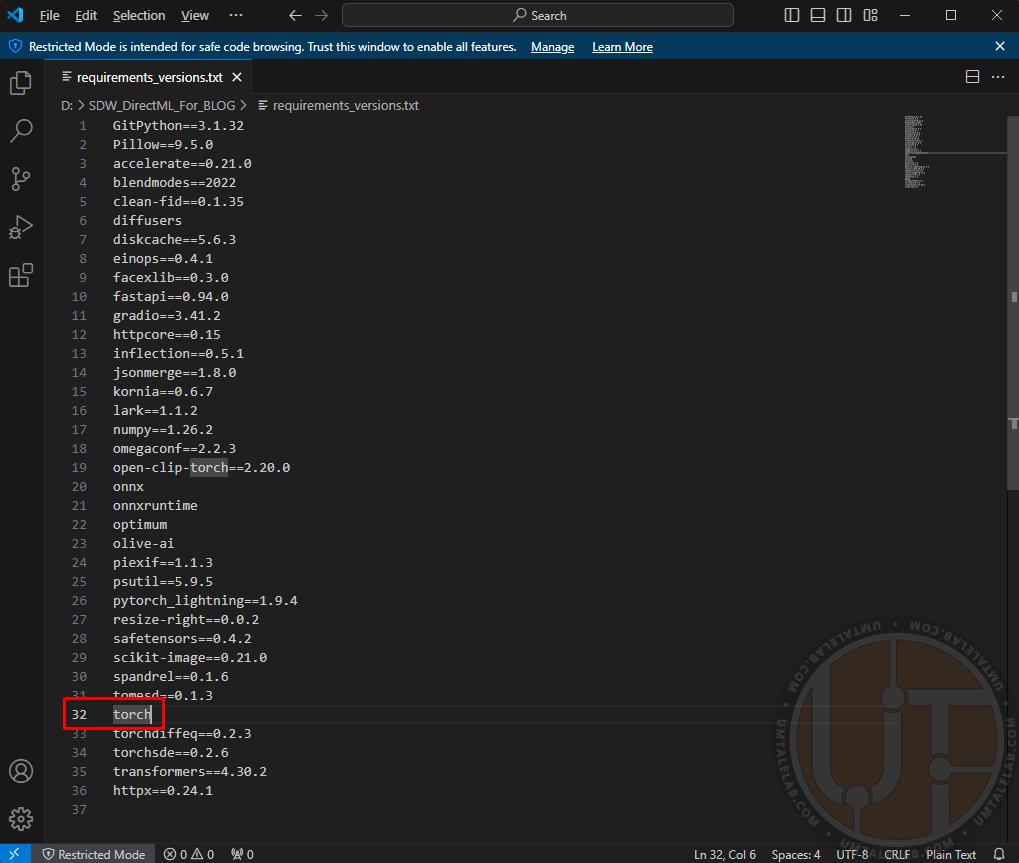
This entry you need to change to torch-directml:

Save and close this file. Next, right-click on the “webui-user.bat” file, then click on “modify/open with Code”. Here you need to add the following argument --reinstall-torch to the parameters already specified earlier:
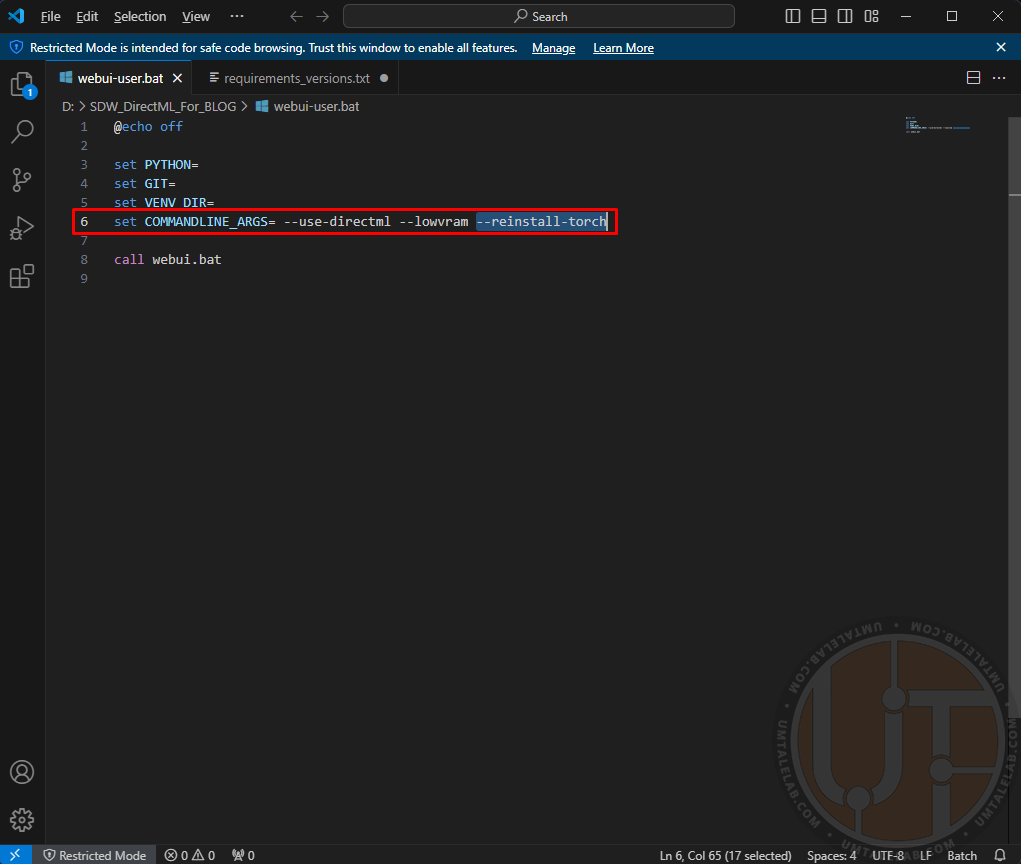
Save and run the same file. In this way we reinstall torch libraries exclusively for DirectML (and CPU, but we are not interested in that).
After the console re-downloads the necessary files and the Stable Diffusion web interface opens, the --reinstall-torch argument from webui-user.bat can be removed.
In my case it helped with the “Torch is not able to use GPU” error on one of the Stable Diffusion WebUI DirectML builds. On another build, it got rid of the problem of using the CPU instead of the AMD graphics card.
Additional settings and examples how Stable Diffusion WebUI works on 4GB and 8GB AMD graphics cards
In this section I will describe my experience of working with neural network on weak AMD graphics cards, as well as give some examples of image generation on R9 270X and RX 470 graphics adapters.
According to my research, only two arguments allow to get a significant performance boost on AMD graphics cards. The first one is --opt-sdp-attention, which, without going into details, is an analog of xFormers for NVIDIA cards, but unlike the latter, works on red graphics adapters as well. --opt-sdp-attention does speed up image generation, but it is far from free. The price for the increased speed is video memory, which, with the DirectML backend, is always in short supply.
The second argument is --upcast-sampling. It speeds up generation slightly, but at the same time it slightly reduces video memory consumption, which is quite appropriate.
Stable Diffusion WebUI launch options for 4GB R9 270X and RX 470 cards:
set COMMANDLINE_ARGS= --use-directml --lowvramFor some reason, the --upcast-sampling parameter only harms cards with small amount of video memory. When using this argument, the generation speed drops by two or three times. Although, judging by the description in the documentation, it seems to be intended to slightly optimize the consumption of the same video memory and speed up generation a bit.
It is impossible to use --opt-sdp-attention on 4 GB video cards at all. Generation does not even start, crashing with an error about critical lack of video memory at almost any resolution.
Sadly, in my case these parameters did not help 4GB cards. Nevertheless, you may well make appropriate experiments on your software and hardware. Perhaps in your case the above mentioned parameters will work adequately on cards with a modest amount of VRAM.
Generation process of one of the images on the Radeon R9 270X at a resolution of 512 by 768 pixels:
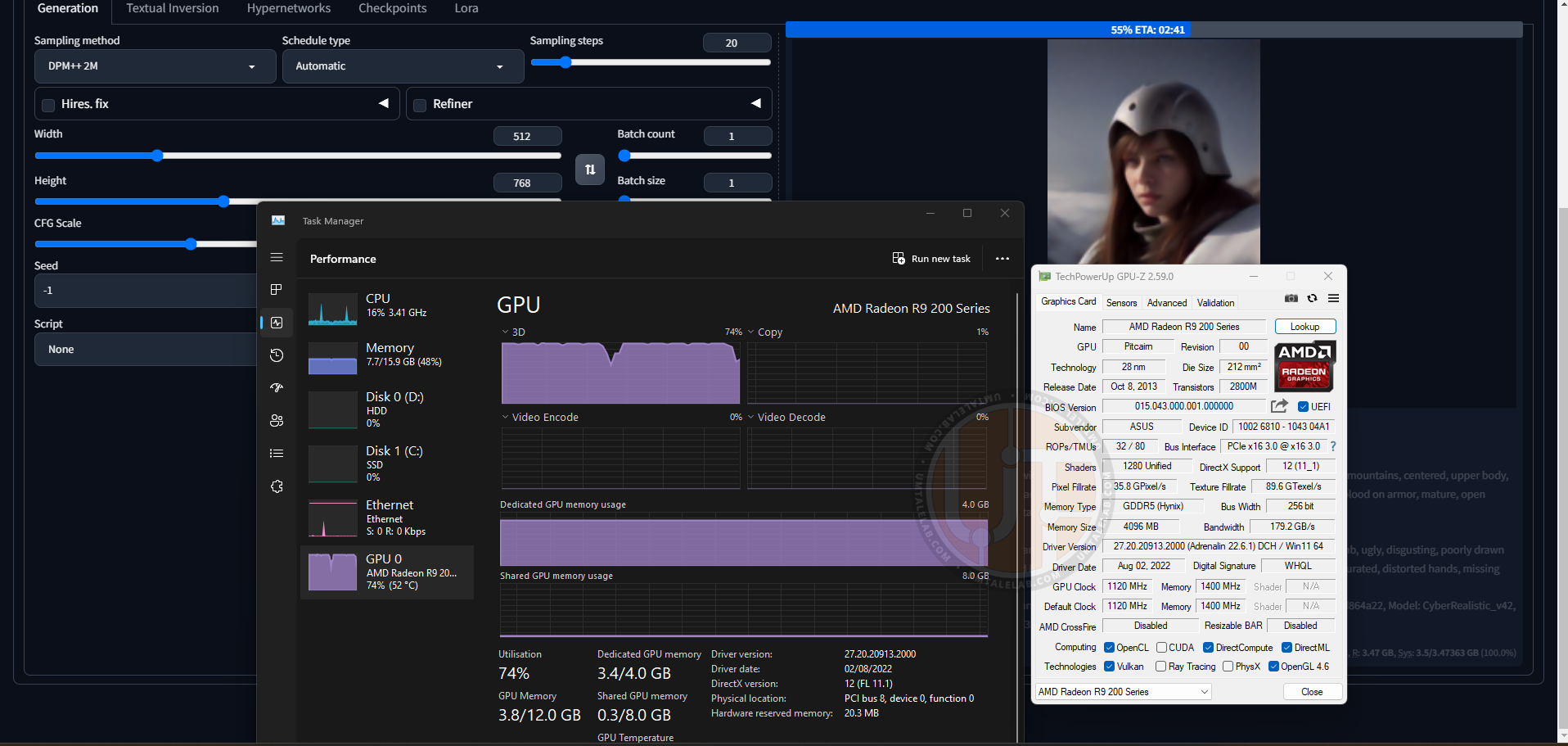
Final result:

Generation time – a little more than 5 minutes, with 20 sampling steps, as well as one connected LoRA. For such an old video card, this is a very good result.
Another final result:

Now let’s see how much the RX 470 4GB will do for with similar settings and resolution:

That’s better, 3 minutes and 23 seconds.
And the most interesting thing I left at the end. In the test bench is an 8GB RX 470.
Stable Diffusion WebUI startup options for 8 GB cards:
set COMMANDLINE_ARGS= --use-directml --medvram --opt-sdp-attention --upcast-samplingIn case of relatively sufficient video memory size, the --opt-sdp-attention and --upcast-sampling parameters work as described in the documentation, and indeed significantly speed up image generation, as well as slightly reduce VRAM consumption.
Without --opt-sdp-attention and --upcast-sampling:

Generation lasted for 2 minutes and 53 seconds. The increase with respect to the 4GB version is not significant at all.
With --opt-sdp-attention and --upcast-sampling:
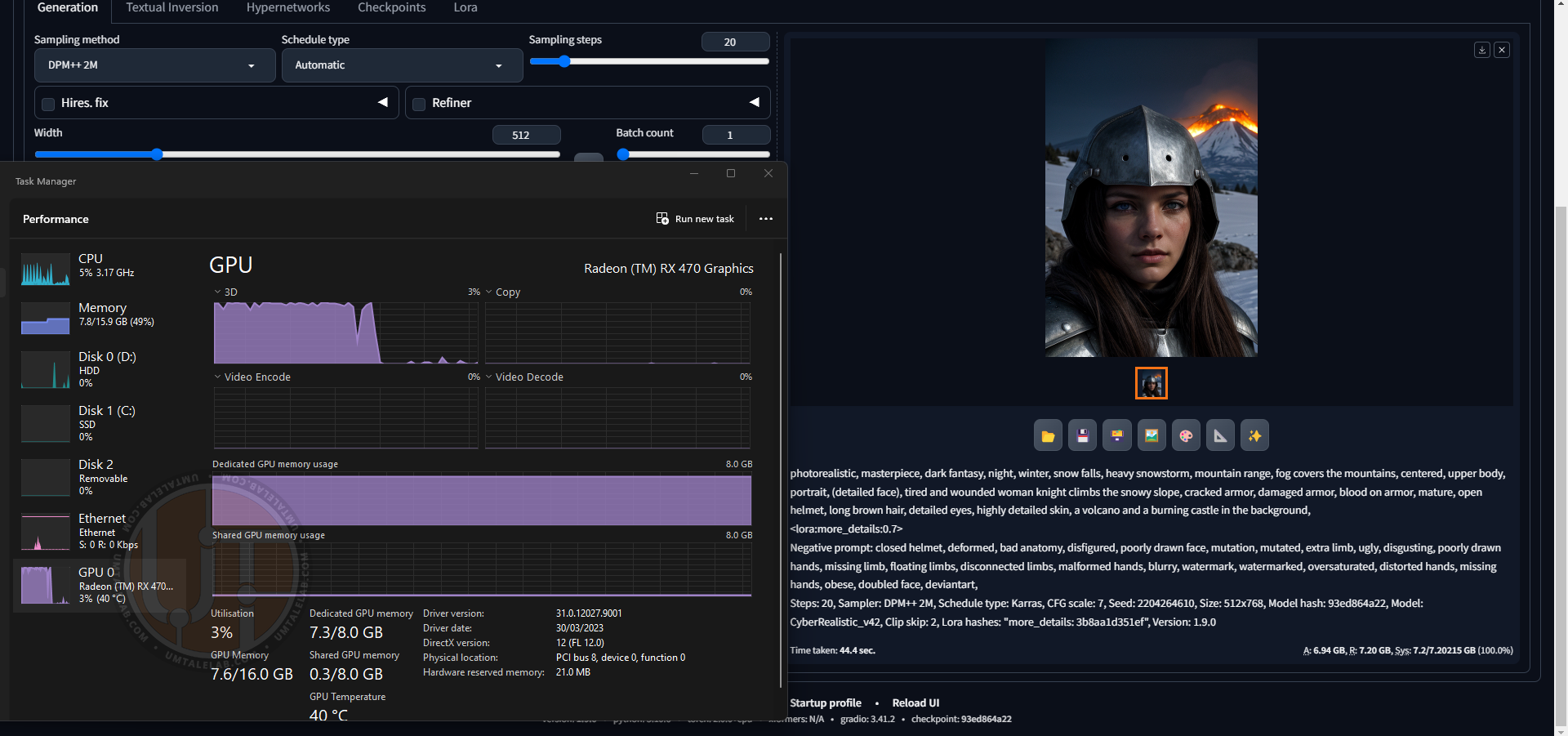
That’s another story – only 44 seconds! Exactly as I wrote at the beginning of the article, the 8GB versions of RX 470/480/570/580/590 will generate images much faster than their 4GB siblings.
Let’s try to increase the resolution a bit to 512 by 900:

53 seconds – an excellent result! But here we have reached the limit of 8 GB video cards. If you want to generate higher resolution images, you need to use the --lowvram argument for a similar amount of VRAM.
Now a bit about minor bugs that generally do not interfere with Stable Diffusion.
From time to time, when generating images in 512×768 / 768×512 resolution (high for AMD cards), the error “RuntimeError: Could not allocate tensor with 1207959552 bytes (or any other number of bytes). There is not enough GPU video memory available!”. This is probably normal for Stable Diffusion WebUI branch with DirectML backend, it doesn’t make much sense to change settings and/or resolution, because after restarting, the generation can start as if nothing had happened, and make even 50 images in a row (with or without batches, it doesn’t matter), and then on the first one it will crash to “RuntimeError” again.
It looks like a problem with “video memory leak”, but I can’t vouch for it, as I haven’t managed to find out the cause of such behavior of WebUI DirectML.
Summary
Undoubtedly, the generation speed on AMD graphics cards, compared to NVIDIA graphics adapters leaves much to be desired. Nevertheless, if you have a card from the red giant installed in your system unit, it is far from being a verdict. According to my research, AMD GPUs (especially those with a relatively large amount of video memory) are capable of generating images quite quickly even with the use of several LoRAs. And if you are the lucky owner of a card with 16, or 24 gigabytes of VRAM, you have access to creating images with higher resolutions, up to FullHD. Perhaps even higher. I don’t have AMD graphics cards with this amount of VRAM in stock right now.
It would be nice to evaluate your image generation results on AMD graphics cards. In addition, if you have information about any extra settings or libraries that can speed up Stable Diffusion on red graphics adapters – feel free to share your experience in comments below!






